

A data foundation is the set of clean, unified, and governed data assets an AI system needs to produce reliable outputs. For a B2B sales and marketing stack, that means accurate contact and company records, deduplicated CRM data, enforced lifecycle stages, and a working attribution model. Without it, AI tools amplify errors rather than detect signals. The term for what that cost is Silo Tax, and it compounds every quarter the foundation stays broken.
When the Tool Works and Nothing Improves
It's a Monday morning, and the AI prospecting tool fired 400 outreach sequences over the weekend.
The RevOps lead opens the performance dashboard. Open rate: acceptable. Reply rate: near zero. The replies that did come in are wrong, wrong company size, wrong job title, one person who left the company six months ago, and clearly no longer works there.
The tool is functioning exactly as designed. It read the data, built the sequences, and sent them. But half the contacts in the system have firmographic fields that were last updated when the data was imported two years ago. A third have job titles for roles people no longer hold. The AI amplified the database, not the opportunity.
The RevOps lead opens a support ticket with the tool vendor. The response: "The platform is working as designed. Please check your CRM data quality."
The problem was never the tool. According to IBM's 2025 research on data quality costs, over a quarter of organizations estimate they lose more than $5 million annually to poor data quality, and 43% of chief operations officers identify data quality as their most significant data priority. The issue isn't AI adoption. The issue is what the AI is running on.
Why This Is Happening to More Teams Than It Should
The opening scene is not a story about one company. It is the pattern.
McKinsey's 2025 State of AI research found that 88% of organizations report using AI in at least one business function, but only about one-third have managed to scale it across the enterprise. The primary blockers for the two-thirds who haven't are fragmented, ungoverned data that AI models cannot work with, workflow rigidity, and operating model inertia. Organizations that see significant financial returns from AI are twice as likely to have redesigned their data workflows before selecting modeling techniques.
Gartner's 2025 research on AI-ready data found that 63% of organizations either do not have or are unsure they have the right data management practices to support AI. Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data.
The structural cause is the Silo Tax, the measurable cost of AI tools running on disconnected, dirty, or incomplete data, forcing rework into every workflow and making signal detection impossible. It is not a tool failure. It is an architecture failure, and it starts upstream of every tool in the stack.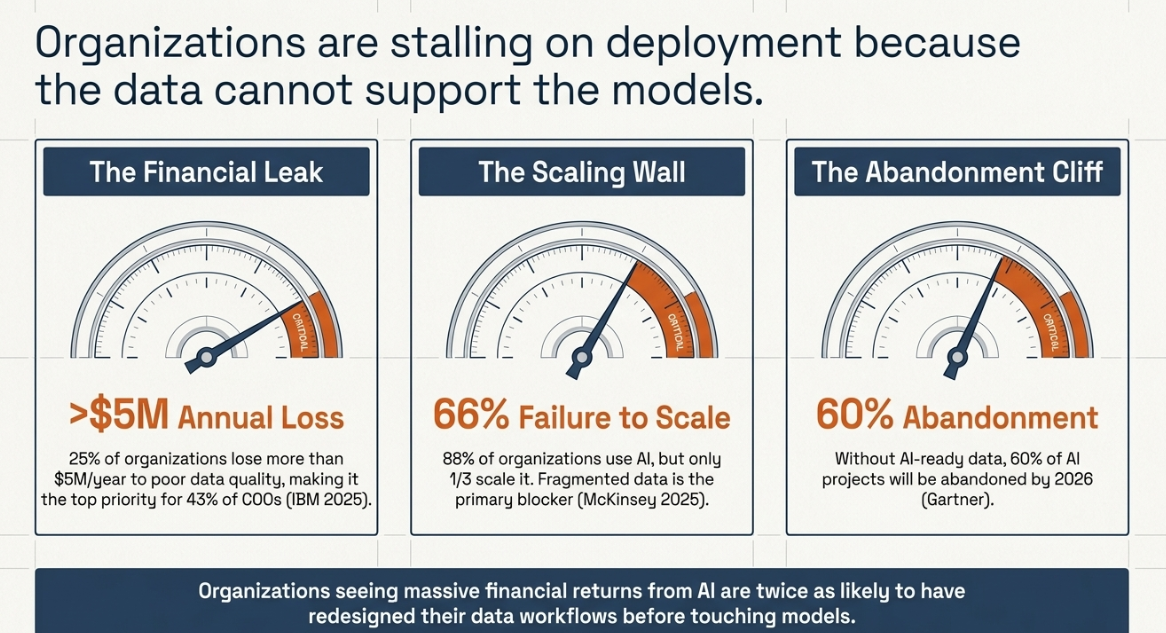
How Do You Know Your Data Foundation Is Broken
Five patterns. Any one of them signals a data foundation problem.
AI lead scoring routes to contacts who are no longer in the role. The model outputs a confident score; the contact left the company in Q3. The AI was accurate given the data it had. The data hadn't been maintained.
Your CRM shows open opportunities that your team knows are dead. The numbers look healthy in the dashboard. The team ignores the dashboard. Forecasting happens in a spreadsheet because nobody trusts what the CRM says.
Marketing and sales attribute the same deal differently. Marketing's report says LinkedIn drove it. Sales says it was the trade show follow-up. Finance is using a third number from Salesforce. Nobody is wrong given their data. Nobody has the same data.
AI prospecting tools fire to accounts already in the active pipeline. The tool doesn't know those accounts are live because the CRM stage data isn't feeding the tool. The outreach fires. The AE finds out when the prospect replies, "Didn't you know we're already in contract discussions?"
You've run AI experiments for 12 months with no measurable pipeline impact. Not bad experiments, the tools were fine. But Forrester's research on data quality and GenAI adoption is direct: "Regardless of which technical path your business pursues, the primary limiting factor you'll face today is your data quality." The experiments ran on noise. Noise produces noise.
B2B contact data decays at approximately 2.1% per month, roughly 22–25% of a clean database becomes outdated within a year, with B2B contact data decay research from Marketing Sherpa and Gartner corroboration putting annual decay at approximately 30%. A CRM cleaned 18 months ago is operating on a database that is materially wrong in one-third of its records.
The Root Cause — What AI Actually Needs from Your Data
AI tools require five specific things from your data environment. Most B2B stacks provide two or three. The gap between what AI requires and what most CRMs deliver is the structural cause of every pattern in the section above.
Clean, complete contact and company records. AI operates on what is in the record. A contact record missing job title, company size, or lifecycle stage gives the AI no basis for intelligent routing. Completeness above 80% on critical fields is the threshold where AI outputs become usable. Below it, the AI is guessing.
Deduplicated CRM with no conflicting records. Duplicate contacts create conflicting histories. The AI sees two versions of the same account, with different engagement data, and cannot determine which is current. Gartner research on the annual cost of poor data quality estimates that poor data quality costs organizations an average of $12.9 million per year — duplication is one of its primary drivers.
Enforced lifecycle stage criteria with consistent entry and exit rules. A deal that moves from "prospecting" to "qualified" because a rep moved it manually, not because a qualifying action occurred, breaks every downstream AI model that uses stage as a signal. Lifecycle stage accuracy is the single most undervalued dimension of data foundation work.
A working attribution model — touchpoints traced to deals. Revenue Intelligence requires knowing which signals preceded closed revenue. Without attribution, the AI has a signal but no ground truth. It cannot learn which behaviors predict conversion because the training data doesn't connect behaviors to outcomes.
Active data governance — not a one-time cleanup. Given the 2.1%-per-month decay rate, a data foundation built in Q1 is a different asset by Q4. Governance is the process that keeps the foundation current: field-level validation rules, import standards, and regular audits. Without it, the data foundation degrades faster than AI tools can compensate.
When these five components are absent or incomplete, the stack accumulates Optimization Debt, the widening gap between what the technology investment costs and what it returns. The debt is silent until the board asks why AI spending hasn't moved the revenue number.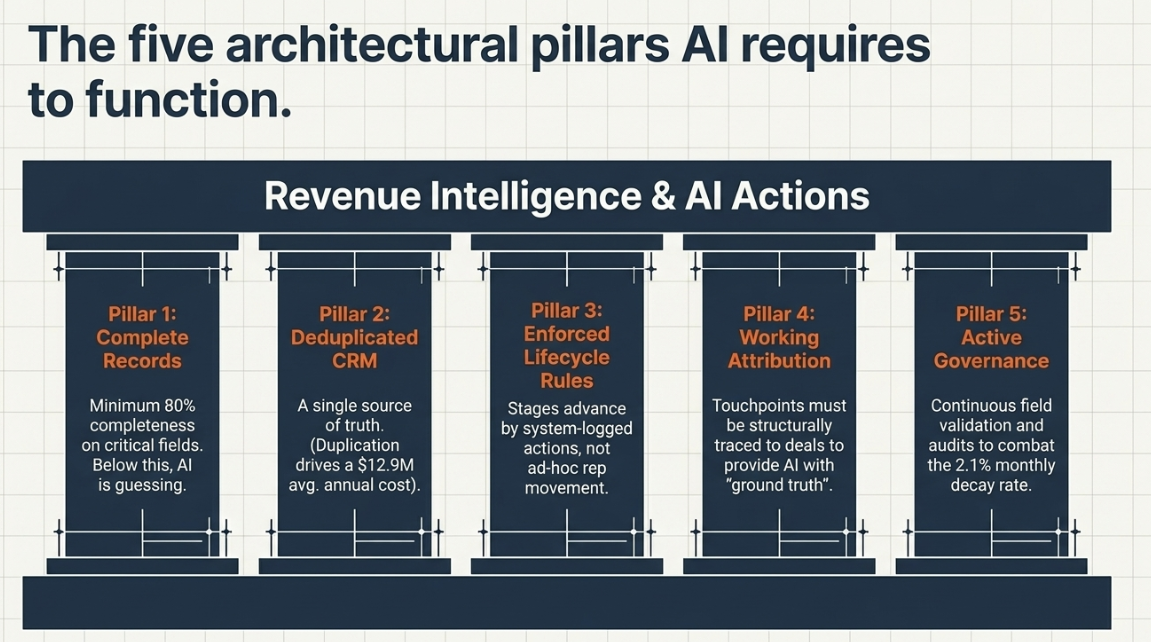
Data Foundation Ready vs. Not Ready
Use this table to run a five-minute self-diagnosis.
|
Dimension |
Ready |
Not Ready |
|
Contact record completeness |
Above 80% of records are complete on critical fields (job title, company, lifecycle stage) |
Below 80%, AI routing will misfire on the gap |
|
Duplicate contact rate |
Below 10% duplicates in the database |
Above 10%, conflicting histories break the AI signal detection |
|
Lifecycle stage accuracy |
Enforced, stages advance only when a qualifying action is logged |
Unenforced or ad-hoc, reps move stages manually without criteria |
|
Attribution model |
Operational, every closed deal is traceable to at least one touchpoint |
Absent or manual, attribution is a post-hoc story, not a data model |
|
AI tool error or misfire rate |
Tracked and below threshold, you know when the AI gets it wrong |
Above threshold or untracked, errors are invisible until a rep reports them |
If two or more rows land in the "not ready" column, the data foundation is the constraint on every AI tool in the stack. Adding more tools or upgrading existing ones will not move the revenue number until those rows flip.
The Recommended Path — How to Build It in Sequence
The sequence matters. Most teams start at step 3. The first two steps are why step 3 doesn't hold.
Step 1: Audit CRM contact and company record completeness. Pull every contact record and run it against a critical field’s checklist: job title, company name, company size, lifecycle stage, and last-touch date. Identify the completion rate. The audit tells you how much of the database is usable as AI input today, and which field categories need the most immediate attention.
Step 2: Deduplicate and standardize existing records. Merge duplicate contacts, normalize company names (the same company entered as "Acme Corp," "Acme Corporation," and "ACME" is three different companies to an AI model), and enforce field formatting standards going forward. This step is time-intensive and cannot be skipped; duplicates corrupt everything downstream.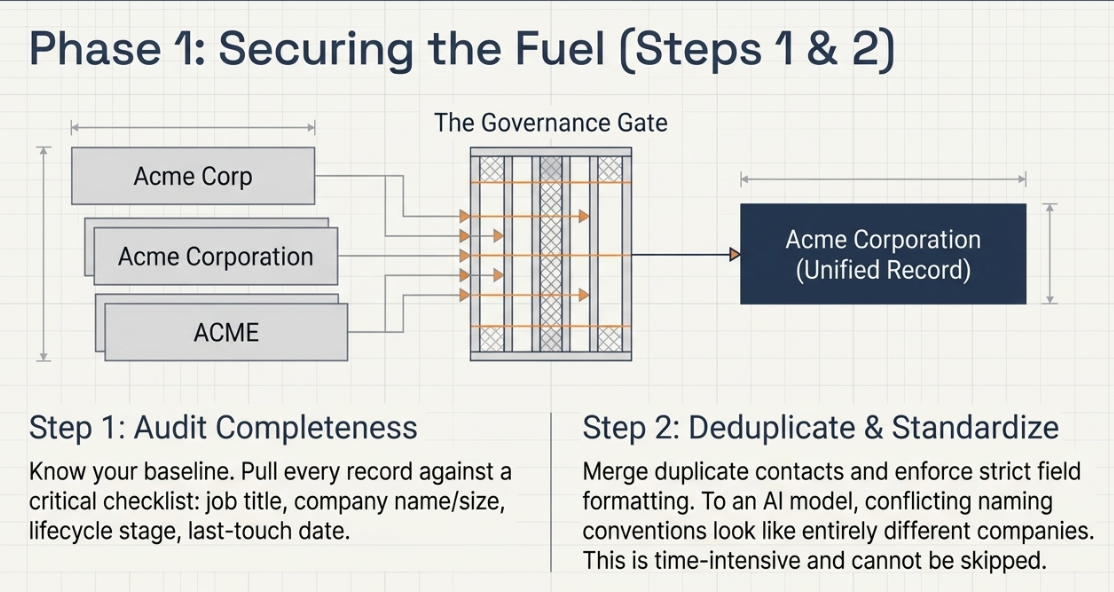
Step 3: Map lifecycle stages across the full buyer journey and enforce stage-entry criteria. Define what action must occur for a record to advance at each stage. Document the criteria. Build validation rules into the CRM so a deal cannot move without meeting the entry condition. This step converts lifecycle stages from a label into a signal.
Step 4: Validate attribution logic. Verify that the CRM can trace which touchpoints preceded each closed deal in the last 12 months. If the attribution model is absent or manual, this step involves retroactive touchpoint mapping and CRM configuration. Revenue Intelligence — the real-time signal detection layer that makes AI worth its investment — requires this step to be working before it can function.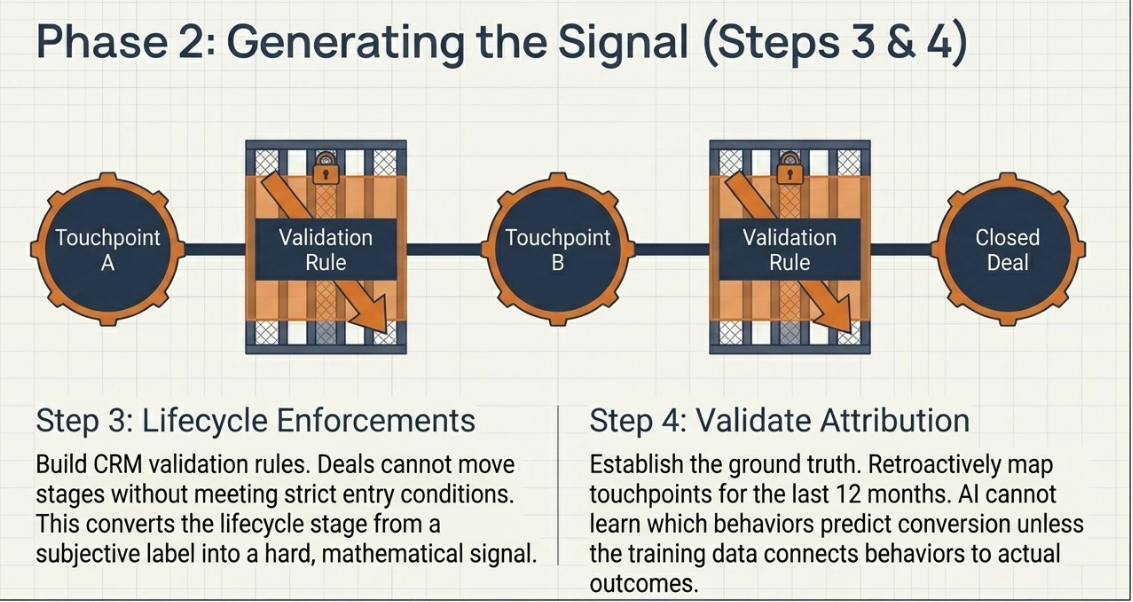
Step 5: Test AI tool inputs against the cleaned data. Before deploying AI tools at scale, run a controlled sample through the tool using only records that have passed steps 1–4. Measure output quality. Compared to baseline. The delta between step 0 and step 5 output quality is the measurable value of the data foundation work.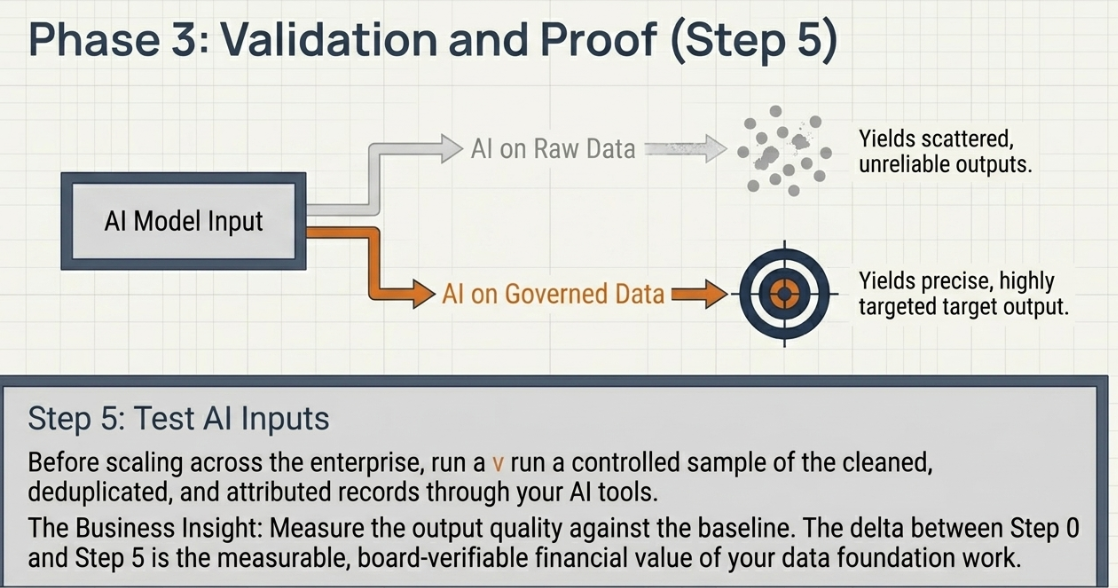
Teams at this stage, actively evaluating whether their data is AI-ready, can accelerate the diagnostic with CETDIGIT's AI Readiness Assessment, a structured diagnostic that maps the current state against the five-component framework above.
This five-step sequence is what enables the transition from system of record to System of Action. A clean, governed data model is not the goal; it is the prerequisite. The goal is an architecture that responds to buying signals autonomously, routes opportunities in real time, and measures outcomes in Cost per Outcome terms that the board can verify.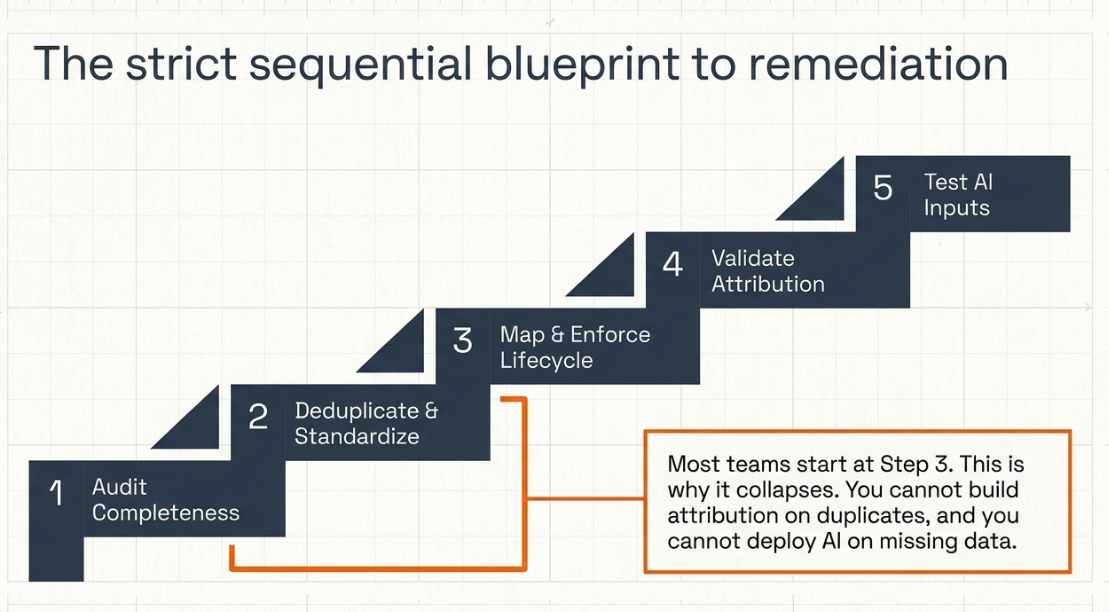
The CETDIGIT Perspective
The data foundation is not a pre-project. It is the first project.
Most AI deployments treat data quality as something to address after the tool is installed, a cleanup task run in parallel while the AI is onboarded. The result is what the opening scene describes: the tool works, the AI fires, and the outputs are confidently wrong. McKinsey's 2025 research is unambiguous: organizations that redesign data workflows before selecting AI models are twice as likely to see measurable returns.
The Cognitive Core, the intelligence layer of a Revenue Engine architecture, requires a unified data model to function. Without complete, deduplicated, and governed data as input, the Cognitive Core has no model to act on. It is a powerful engine running on contaminated fuel. The data foundation is not a technical prerequisite. It is the input layer that determines whether the entire downstream architecture produces Revenue Intelligence or produces noise.
CETDIGIT's Data and AI Foundation services are built around this sequence, auditing what the current stack actually contains, closing the field-completeness and deduplication gaps, building the attribution model, and validating the result against AI tool inputs before any new AI investment is made. This fits within CETDIGIT's AI services architecture as the foundational layer underneath sales workflow automation, voice agent deployment, and revenue engine orchestration, the work that makes all of those investments return their value.
The AI Revenue Engine is what a clean data foundation makes possible: a connected architecture where buying signals are detected in real time, workflows fire autonomously, and outcomes are attributable to specific actions. Getting there starts with knowing what the data says right now, and what it is missing.
Frequently Asked Questions
What data foundation do you need before AI?
A data foundation for AI requires five components: clean and complete contact and company records (above 80% field completeness on critical fields), a deduplicated CRM with no conflicting records, enforced lifecycle stage criteria with consistent entry and exit rules, a working attribution model that traces deals to touchpoints, and active data governance that maintains the foundation over time. Gartner's 2025 research predicts that 60% of AI projects without this foundation will be abandoned through 2026.
Why does AI fail with bad CRM data?
AI tools do not evaluate data quality; they operate on whatever is in the record. A contact with an outdated job title and wrong company size feeds the AI a confident signal that points in the wrong direction. The AI performs as designed; the output is wrong because the input is wrong. Forrester's research identifies data quality as the primary limiting factor in GenAI deployment, ahead of model quality, compute, or talent. The tool is rarely the problem.
What does AI need to work in a sales and marketing stack?
At minimum: accurate contact records it can route against, lifecycle stage data it can use as signals, an attribution model it can learn from, and governance that keeps those inputs current. Without lifecycle stage accuracy and attribution logic, an AI tool has activity data but no ground truth; it cannot determine which behaviors predict conversion because the training signal doesn't connect behaviors to outcomes. Revenue Intelligence requires all four inputs to function.
How do I prepare my CRM data for AI?
Follow the five-step sequence: audit contact and company record completeness; deduplicate and standardize existing records; map lifecycle stages and enforce stage-entry criteria; validate attribution logic; test AI tool inputs against the cleaned data before deploying at scale. Do not skip steps 1 and 2; they are why steps 3 through 5 hold over time. The five-step framework is detailed in the Recommended Path section above.
What is the Silo Tax?
The Silo Tax is the measurable cost of AI tools running on disconnected, dirty, or incomplete data, where the disconnection forces rework into every workflow and makes signal detection impossible. It is the financial framing of what happens when AI is deployed before the data foundation is in place: the tools add latency and cost rather than accelerating revenue. Gartner estimates the cost of marketing-sales data silos at 10–15% of revenue annually.
How often does CRM data go out of date?
B2B contact data decays at approximately 2.1% per month, meaning roughly 22–25% of a clean database is outdated within a single calendar year. Gartner research corroborates this with an approximately 30% annual decay figure. For a CRM that hasn't been systematically maintained in 18 months, over a third of contact records likely contain material inaccuracies. Without active data governance, the foundation degrades faster than any AI tool can compensate.
What is a data foundation for AI?
A data foundation is the set of clean, unified, and governed data assets an AI system needs to produce reliable outputs. It is not a software product; it is a state of the data. For a B2B sales and marketing stack, it means accurate records, no conflicting duplicates, enforced lifecycle stages, traceable attribution, and active governance to maintain accuracy over time. It is the prerequisite for every AI investment in the stack, and the first place to look when AI tools are not producing measurable results.
Stack Unification Audit
Find out exactly where your data is breaking AI, and what to fix before you invest another dollar in tools. Book a Stack Unification Audit. We'll map your current data foundation against the five-component framework, identify exactly which gaps are blocking your AI tools from producing Revenue Intelligence, and build the sequence for closing them.



Leave a Comment