
User intent is the key to successful marketing and sales in today’s business market. When your customers search for solutions to their problems, they do so with a purpose or an intent. What this intent is will vary from visitor to visitor, but this piece of information is what ultimately drives a customer to a sale. Because of this, your business needs to understand the needs of each of its customers and prospects. Fortunately, most customers fall into four basic categories: anonymous, intensive, lapsed, and repeat. Each type of customer has its own needs and requirements. However, if you can integrate this information, your organization would reap the benefits of many successful business campaigns.
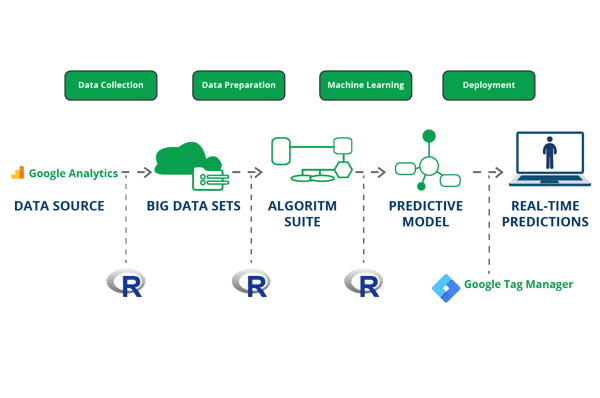
Kinds of Users that visit a website and their data
Your website is your primary source of user intent data. It is where your customers first contact your company, and, in recent years, the only way most of them will interact with you. However, until these customers sign up and log into your website, you have no way to identify them. They are just anonymous visitors at this point.
Anonymous visitors are anyone you do not have identifying information about. They can be anonymous because they are new customers, or they have yet to log into your services. Either way, you can only interact with them in generic, public ways.
Fortunately, most websites come equipped with enough solutions to track these anonymous visitors as well as the intensive, lapsed, and repeat customers they can become, for you. This data includes their perusing conduct, the recurrence of visits, what they are keen on, and so forth.
Most of the data your website collects can create and deliver several types of contextualized messages to these visitors already.
Your current intensive customers sound like your best customers to understand. This makes it considerably easier to pitch sales to your existing customers. You already have their information in your database. You should already have the action rate, buy conduct, and channel inclinations you need to create accurate client profiles for them, increasing any ROI from their transactions. Thus, you want to maximize your marketing efforts with your already existing customers.
However, customers can become inactive. They might not need your services at the moment, or they could be waiting on something or someone else before they purchase from you again. In either case, you can coax these lapsed customers back into being active again and it is all in their user intent data. You can check in on them using email, or an appropriate alternative channel, to help them find ways to use your services to fulfill their current needs. Even if you do not make a sale, such efforts will prepare your organization for when these customers become returning customers again.
Returning and regular visitors are almost interchangeable, and both groups offer similar user intent. This data includes their search and transactional history, how they move through your website, the time they spend on past visits, and how they typically reach your website as well as the devices and software they use to browse your website. Other important information you can gather from these customers is where they live and how they interact with others. All this information allows you to tailor your message to their specific needs and situations.
Collection of Data
You can collect your customers’ user intent from their various website sessions directly from self-reported forms, digitally collected browsing behavior, profiled cookie matching, etc. You can even collect the data from every visit or track every interaction within a single visit.
Some of the data you should consider collecting include:
- Click streams
- Customer location
- Behavioral data
- Device type
- Number of past visits
- The duration of each visit
Gathering this information is easy. You have several collection methods at your disposal including cookie matching, browsing activity tracking, reverse ip identification, data on-boarding and contextual targeting.
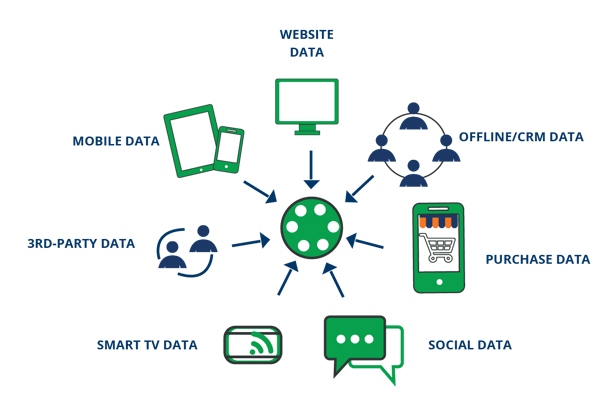
Preprocessing and Preparation of the Data
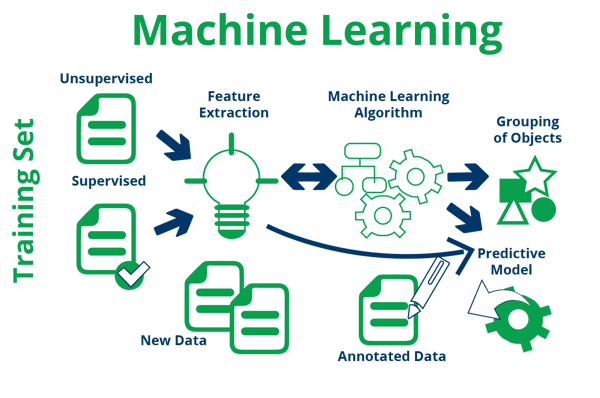
With our relevant user data in hand, we can transform it into something our machine learning algorithms can use. We must do this task as most raw data is not directly compatible with most numerical learning models.
For example, if we want to implement a Support Vector machine model on our data, we cannot use categorical variables (String/Text). Also, we should normalize the data to numbers between 0 and 1, so that our model can work with it effectively.
Beyond the structure problem, our user intent data have other issues we must deal with before you can use it in models. For instance, we can collect more data on our users than we need. This extra useless data will just slow down our models and learning algorithms, making them virtually useless for making predictions. Thus, we must make sure we are only collecting the items we need before we try them within our models.
Once done, our dataset will be ready for processing. We then have one more step before we can turn on our machine learning tools and start using the data, and that is splitting the data into the three subsets our algorithms need.
These three subsets are:
- Training data (60 to 80 percent of the dataset)
- Testing Data (10 to 20 percent of the dataset)
- Validation data (10 to 20 percent of the dataset)
Implementation of Machine Learning Algorithm
Now, we are ready to start using machine learning to find our user intent, but not all machine learning algorithms are equal. Each algorithm has its best use cases, and we should try limiting them to those cases. For instance, we want to use neural networks (both deep and shallow) on our website’s search text data. We can also use algorithms like SVM and Naïve Bayes.
From there, the algorithms we need will largely depend on the insights we want. Our data and machine learning tools can show us the world, but that might be too much information for our needs. Because of this, you should be mindful of your final outcome when selecting the algorithm.
For instance, we can do a qualitative and quantitative analysis to create rules to personalize customer experience. On the other hand, if we want to focus our predictive modeling on a subset of the most promising prospects, we can perform data exploration and use domain expertise for choosing an appropriate subset.
However, for complicated and large-scale datasets, deep understanding of data by exploration can be rather limited. Additionally, domain expertise may be not always available. Therefore, we should directly evaluate every subset of our target through predictive accuracy testing as an alternative to our usual straight forward context selection
Beyond these basics, here are a few other common machine learning algorithms and methodologies:
- Clustering the users with similar behavior or similar intentions.
- Analyzing the profile sequence for each user over the whole period to get better insights into how the user behaves throughout the session.
- All the users having same intention of visiting a website will have mostly same properties or same features so they will fall into the same clusters.
- Giving a tree like structure to each user for the sites they are visiting or the actions they are performing on the website.
- Using generative mixture models for predicting the user profiles and behavior based on the historical tree or the transaction data.
- The idea behind using the mixture model is that it is a way of representing more complex probability distribution model in terms of simpler model.
- Basically using a Bayesian framework for parameter estimation and the mixture model addresses the heterogeneity of page visits.
In the clustering technique, we use similarity metrics between clickstreams data to build similarity graphs to capture behavioral patterns between users. We then use hierarchical clustering to detect the most common behavioral patterns while filtering out the most dominant features. This technique draws the most common behavior to the top because those behavioral patterns are more generalized among your customers .With a properly clustered group of customers, we can present the entire group a tailored advertisement or campaign each time we receive a new customer that falls within it.
There are benefits to retrieving users intention
Your customers appreciate a more personalized experience, but that is not the only reason for retrieving and using your users’ intention to improve your customer interactions. You can use the information to improve the design of your website with personal search suggestions and recommendations. This will let you present your customers the right solution and make better use of your budget. Your user intent data will also show you where you can concentrate your marketing efforts to ensure the success of every campaign you implement. All this is possible with the right machine learning algorithms and data processing tools.
-1.png?width=600&name=image%205%20(1)-1.png)



Leave a Comment